
Wyobraź sobie jeden centralny punkt kontaktu dla klientów, pracowników i partnerów biznesowych. Działa we wszystkich kanałach - telefon, czat, WhatsApp, e-mail. Obsługuje dowolny język. Pracuje 24 godziny na dobę, 7 dni w tygodniu, 365 dni w roku. Nie ma kolejek, nie ma sygnału zajętości, nie ma "proszę czekać, połączę z konsultantem". To właśnie AI Communication Center.
Eliminuje wieczne czekanie w kolejce. Eliminuje utracone leady, bo nikt nie odebrał. Eliminuje frustrację klientów, którzy dzwonią po godzinach i słyszą automat. Centrum komunikacji AI odbierze zawsze. Spróbuje pomóc samodzielnie. Jeśli nie da rady - płynnie przełączy do człowieka. A jeśli to niemożliwe (np. poza godzinami pracy) - przyjmie zgłoszenie lub zarejestruje prośbę o oddzwonienie. Żadne zapytanie nie zostaje bez odpowiedzi.
Niniejszy playbook przedstawia kompleksowe podejście do projektowania i wdrażania takiego systemu. Nie jest to podręcznik techniczny o promptach i architekturze systemowej. To materiał strategiczny dla biznesu, ale jednocześnie bardzo operacyjny - z konkretnymi scenariuszami, checklistami i frameworkiem wdrożeniowym.
Skuteczne centrum komunikacji AI nie opiera się na jednym bocie. Opiera się na dobrze zaprojektowanym systemie decyzji - kto odpowiada na jaki typ sprawy, na jakiej wiedzy pracuje, kiedy kończy sprawę sam, a kiedy i jak przekazuje ją człowiekowi. Centralny punkt kontaktu, który nigdy nie śpi i nigdy nie traci cierpliwości.
Czym naprawde jest AI Communication Center
Wielu menedżerów wciąż utożsamia sztuczna inteligencje w obsludze klienta z prostymi chatbotami, które potrafią jedynie odpowiadać na najczęściej zadawane pytania. Tymczasem nowoczesne centrum komunikacji AI to zaawansowany system obsługi intencji, decyzji i przełączeń. Jego głównym celem nie jest tylko udzielenie odpowiedzi, ale rozwiązanie problemu klienta (resolution).
AI Communication Center działa jako warstwa operacyjna, która integruje różne kanaly komunikacji i zarzadza przepływem informacji. Agenci AI potrafią analizowac kontekst rozmowy, rozpoznawać intencję uzytkownika i podejmowac decyzję o kolejnych krokach. Jeśli sprawa jest prosta - agent rozwiązuje ja samodzielnie. Jeśli wymaga interwencji człowieka - płynnie przekazuje ją do odpowiedniego konsultanta, dostarczając mu pełny kontekst dotychczasowej interakcji.
To przejście z poziomu „AI = chatbot” na poziom „AI = warstwa operacyjna komunikacji”. Centrum komunikacji AI łączy w sobie architekturę agentów, zarządzanie wiedzą, inteligentny routing i płynną współpracę z zespołem ludzkim. To właśnie takie podejście reprezentuje platforma X-TALK.
Gdy klient dzwoni lub pisze, jego wiadomość przechodzi przez szereg etapów przetwarzania. Zrozumienie tego pipeline'u jest kluczowe dla projektowania skutecznego systemu.
W kanale tekstowym (czat, WhatsApp) pomijane są kroki STT i TTS. W kanale głosowym każdy krok dodaje latencję - dlatego optymalizacja pipeline'u jest kluczowa dla płynności rozmowy.
Niedoskonałości STT - o czym trzeba wiedzieć
Speech-to-Text to krytyczny element pipeline'u głosowego, ale nie jest doskonały. Silniki STT próbują dopasować dźwięki do słów ze swojego słownika, co prowadzi do charakterystycznych problemów:
"no", "czemu", "tak" są często błędnie interpretowane lub pomijane. STT potrzebuje kontekstu - im krótsza wypowiedź, tym mniej danych do analizy."9", "12" czy kody pocztowe są problematyczne. STT często myli "dziewięć" z "dziewięciu" lub interpretuje cyfry jako słowa.Najgorszy scenariusz to nie błędna transkrypcja - to brak transkrypcji. Zdarza się, że klient odpowiada krótko - "ok", "tak", "mhm" - a silnik STT po prostu to ignoruje. Nie generuje żadnego tekstu. System czeka na transkrypcję, która nigdy nie przychodzi.
Kluczem jest parafraza - zamiast powtarzać to samo pytanie, agent przeformułowuje je tak, żeby klient odpowiedział pełnym zdaniem. To jednocześnie rozwiązuje problem STT i sprawia, że rozmowa brzmi naturalnie.
Wniosek: projektowanie dialogu AI to nie tylko UX - to bezpośrednio wpływa na dokładność STT, jakość rozpoznawania intencji i ostatecznie na skuteczność całego systemu.
Panel 'Moi agenci' pozwala zarządzać wieloma wyspecjalizowanymi agentami AI. Każdy agent ma własną rolę, baze wiedzy i statystyki. To nie jest jeden bot - to zespol agentów, z których każdy ma jasno określoną specjalizację.
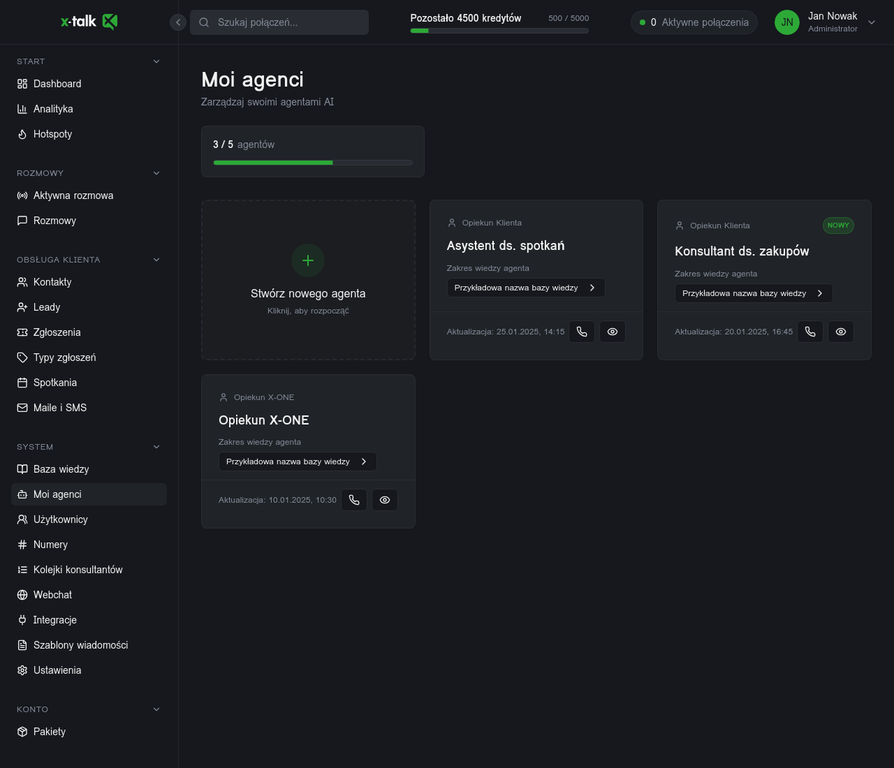
Panel zarządzania agentami AI - każdy agent ma dedykowaną rolę i baze wiedzy
Od kanałów do architektury komunikacji
Pierwszym krokiem w projektowaniu centrum komunikacji AI jest identyfikacja i analiza dostępnych kanałów kontaktu. Klienci moga kontaktować się z firma poprzez wiele różnych drog, a każda z nich ma swoja specyfike i wymaga odpowiedniego podejścia.
| Kanal | Specyfika | Priorytet automatyzacji |
|---|---|---|
| Strona www / czat | Najwyższy wolumen, często proste pytania | Wysoki - naturalny punkt startowy |
| Telefon / voice | Złożone sprawy, wysoki koszt obsługi | Wysoki - duży potencjał oszczędności |
| Formalny, asynchroniczny, wymaga kontekstu | Średni - klasyfikacja i routing | |
| WhatsApp / Messenger | Szybki, nieformalny, popularny w B2C | Wysoki - powtarzalne zapytania |
| Formularze | Strukturyzowane dane, intake zgłoszeń | Średni - automatyzacja follow-up |
| Service desk / BOK | Wewnętrzne procesy, ticketing | Średni - wsparcie konsultantów |
Decyzja o tym, które kanaly automatyzowac w pierwszej kolejności, powinna opierać się na analizie wolumenu zapytań i ich powtarzalności. Kanaly o największym natężeniu prostych, powtarzalnych spraw są naturalnymi kandydatami do automatyzacji. Warto również uwzględnić preferencje klientów i specyfike branży.
Zacznij od kanału, w którym masz największy wolumen powtarzalnych spraw. Najczęściej jest to czat na stronie lub telefon. Jeden dobrze wdrożony kanał da Ci więcej niż pięć wdrożonych pobieżnie.
Typy spraw i mapa intencji
Kluczowym elementem skutecznego centrum komunikacji AI jest umiejętność rozpoznawania intencji klienta i klasyfikowania spraw. Bez precyzyjnej mapy intencji nawet najlepszy model jezykowy nie będzie wiedział, jak prowadzić rozmowe. Mapa intencji to fundament, na którym buduje się cały system decyzji.
| Kategoria | Opis | Przykłady | Automatyzacja |
|---|---|---|---|
| FAQ | Najczęściej zadawane pytania, proste informacje | Godziny otwarcia, koszty dostawy, warunki zwrotu | Pełna |
| Sprzedaż | Zapytania o ofertę, pomoc w wyborze | Dostępność produktu, parametry, porównanie | Częściowa + handoff |
| Obsługa posprzedażowa | Status zamówienia, śledzenie przesyłki | Gdzie jest moja paczka? Kiedy dostawa? | Pełna (z integracją) |
| Zgłoszenia / reklamacje | Problemy z produktem lub usługą | Uszkodzony towar, błąd w rozliczeniu | Intake + eskalacja |
| Kwalifikacja leada | Zbieranie danych i określanie potrzeb | Prośba o wycenę, demo, konsultacje | Pełna + przekazanie |
| Eskalacje | Sprawy wymagające interwencji człowieka | Niezadowolony klient, problem prawny | Routing + kontekst |
Stworzenie szczegółowej mapy intencji pozwala na precyzyjne zaprojektowanie ścieżek obsługi i przypisanie odpowiednich kompetencji agentom AI. To jeden z najważniejszych etapów przygotowania - bez niego wdrożenie będzie chaotyczne, a klienci będą trafiać na ślepe zaułki w rozmowach.
Przeanalizuj 500–1000 ostatnich interakcji z klientami. Pogrupuj je w kategorie. Zobaczysz, że 80% zapytań mieści się w 10–15 typach spraw. To właśnie od nich zacznij projektowanie agentów.
Jak przygotować baze wiedzy
Skuteczność agentów AI zależy w duzej mierze od jakości wiedzy, na której pracuja. Nawet najlepszy model jezykowy nie udzieli trafnej odpowiedzi, jeśli nie będzie mial dostepu do aktualnych, dobrze zorganizowanych informacji. Baza wiedzy to paliwo, na którym działa cały system.

| Typ wiedzy | Opis | Źródła |
|---|---|---|
| Publiczna | Informacje dostępne dla wszystkich | Strona www, FAQ, regulaminy, cenniki |
| Procesowa | Procedury i zasady działania firmy | Instrukcje obsługi, workflow, SOP |
| Operacyjna | Dane z systemów i narzędzi | CRM, ERP, helpdesk, e-commerce |
| Ekspercka | Specjalistyczne know-how | Doświadczenie konsultantów, case studies |
Proces przygotowania bazy wiedzy obejmuje identyfikację zrodel, czyszczenie i strukturyzację danych, a także wdrożenie mechanizmow wersjonowania i aktualizacji. Wiedza musi być opisana w sposób zrozumiały dla modeli jezykowych, co ułatwi im wyszukiwanie i generowanie trafnych odpowiedzi. Nie chodzi o to, żeby „wrzucic wszystko do systemu” - chodzi o to, żeby dostarczyć właściwa wiedzę we właściwym momencie.
Kluczowa zasada: dziel dokumenty per funkcja, problem lub obszar. Jeden duzy dokument z całym know-how firmy to najgorsze, co można zrobic. Dlaczego? Mechanizm RAG (Retrieval-Augmented Generation) wyszukuje fragmenty tekstu najblizsze zapytaniu klienta. Jeśli całą wiedza jest w jednym pliku, system musi przeszukiwac ogromna ilość tekstu, a trafność dopasowania spada dramatycznie.
- ✕RAG przeszukuje cały tekst - niska precyzja
- ✕Fragmenty z różnych tematów mieszaja się
- ✕Trudno aktualizowac pojedyncze sekcje
- ✕Model dostaje szum informacyjny
- ✕Wyższy koszt przetwarzania tokenów
- ✓RAG trafia precyzyjnie w odpowiedni dokument
- ✓Każdy dokument ma jasny kontekst
- ✓Latwa aktualizacja pojedynczych procedur
- ✓Model dostaje czysta, relevantną wiedzę
- ✓Niższy koszt, szybsze odpowiedzi
Przykład: zamiast jednego pliku „Wszystko o obsludze klienta.pdf” (200 stron), przygotuj osobne dokumenty: „Procedura zwrotu towaru”, „Reklamacja - uszkodzenie w transporcie”, „Zmiana adresu dostawy”, „Status zamówienia - FAQ”. Każdy dokument 1–3 strony, z jasnymi metadanymi i struktura.
- Zidentyfikuj wszystkie źródła wiedzy w organizacji
- Oczyść dane z duplikatów, nieaktualnych informacji i sprzeczności
- Podziel wiedzę na kategorie (publiczna, procesowa, operacyjna, ekspercka)
- Rozbij duże dokumenty na mniejsze - per procedura, per problem, per obszar
- Opisz każdy fragment wiedzy metadanymi (temat, aktualność, zastosowanie)
- Wdróż proces regularnej aktualizacji i wersjonowania
- Przetestuj jakość odpowiedzi na próbce rzeczywistych pytań klientów
Jak pisać dokumenty dla RAG - porzuć stare nawyki
Wiele firm, które wcześniej korzystały z tradycyjnych voicebotów lub systemów IVR, ma bazę wiedzy przygotowaną w stylu „krótkie hasło → krótka odpowiedź”. To zrozumiałe - stare systemy opierały się na keyword matching i drzewach decyzyjnych, więc potrzebowały precyzyjnych, telegraficznych fraz. Problem w tym, że ten styl jest przeciwskuteczny w systemach RAG.
Silnik RAG, który zbudowaliśmy w X-TALK, działa na zasadzie embeddingów semantycznych - zamieniają tekst na wektory matematyczne i szukają znaczeniowego podobieństwa między pytaniem klienta a dokumentami w bazie. Im bogatszy kontekst dokumentu, tym lepsze dopasowanie. Krótkie hasła bez kontekstu to dla embeddingów „szum” - system nie ma się za co „zaczepić”.
RAG semantyczny lepiej radzi sobie z obszerniejszym, kontekstowym tekstem niż z krótkimi hasłami. Dłuższy dokument z opisem problemu, przyczynami i rozwiązaniem daje silnikowi więcej punktów dopasowania. Krótkie hasło „reset hasła” może pasować do 20 różnych kontekstów. Pełny opis procedury z symptomami i krokami - trafia precyzyjnie.
Odp: Proszę kliknąć „Nie pamiętam hasła” na stronie logowania.
Odp: Konto zostaje odblokowane po 30 minutach.
Odp: Sprawdź czy Caps Lock jest wyłączony.
• Brak kontekstu - embedding nie wie, o co chodzi
• Trzy osobne hasła na jeden problem
• Odpowiedzi są fragmentaryczne i niepełne
• Klient musi trafić w dokładne słowo kluczowe
• Bogaty kontekst - embedding rozumie temat
• Jeden dokument pokrywa cały problem
• Symptomy w YAML boostują dopasowanie
• Klient może opisać problem swoimi słowami
H: zwrot
O: Zwroty realizujemy w ciągu 14 dni.
H: jak zwrócić
O: Wyślij formularz zwrotu na adres...
H: pieniądze za zwrot
O: Zwrot środków w 5-7 dni roboczych.
Klient pyta: „Kupiłam buty tydzień temu, są za małe, co mogę zrobić?” → System nie trafia, bo nie ma hasła „buty za małe”.
Procedura zwrotu towaru
Klient chce zwrócić zakupiony produkt. Może to być spowodowane niewłaściwym rozmiarem, niezgodnością z opisem, zmianą decyzji lub wadą produktu. Zwrot jest możliwy w ciągu 14 dni od otrzymania przesyłki...
[+ pełna procedura krok po kroku, wyjątki, FAQ]
To samo pytanie → RAG rozumie semantycznie „buty za małe” = „niewłaściwy rozmiar” = „zwrot towaru”. Trafia precyzyjnie.
| Cecha | Keyword matching (stary styl) | RAG semantyczny (nowy styl) |
|---|---|---|
| Format dokumentów | Krótkie hasła + krótkie odpowiedzi | Pełne dokumenty z kontekstem i strukturą |
| Dopasowanie | Dokładne trafienie w słowo kluczowe | Semantyczne podobieństwo znaczeniowe |
| Synonimy | Trzeba ręcznie dodać każdy synonim | System rozumie synonimy automatycznie |
| Pytania klienta | Musi trafić w dokładną frazę | Może opisać problem swoimi słowami |
| Obsługa kontekstu | Brak - każde hasło jest izolowane | Rozumie kontekst całego dokumentu |
| Skalowalność | Setki haseł do utrzymania | Dziesiątki dokumentów pokrywają więcej scenariuszy |
| Aktualizacja | Edycja wielu haseł przy jednej zmianie | Aktualizacja jednego dokumentu |
| Koszt utrzymania | Wysoki - ciągłe dodawanie haseł | Niski - dokumenty rosną organicznie |
Praktyczna rada: jeśli migrujesz z tradycyjnego voicebota na system RAG, nie przenoś starej bazy „hasło → odpowiedź” w niezmienionej formie. Zamiast tego zgrupuj powiązane hasła w pełne dokumenty proceduralne. Na przykład: 20 haseł dotyczących zwrotów, reklamacji i wymiany zamień w 3–4 dokumenty: „Procedura zwrotu towaru”, „Reklamacja - uszkodzenie w transporcie”, „Wymiana na inny rozmiar”, „Zwrot środków - metody i terminy”. Każdy dokument 1–3 strony, z pełnym kontekstem, symptomami i krokami.
Nasz silnik embeddingów zamienia tekst na wektory w przestrzeni wielowymiarowej. Im więcej kontekstu ma dokument, tym precyzyjniej zostaje umieszczony w tej przestrzeni. Krótkie hasło „zwrot” może oznaczać zwrot towaru, zwrot pieniędzy, zwrot podatku, zwrot paczki - embedding nie wie, o który chodzi. Pełny dokument „Procedura zwrotu towaru zakupionego online” z opisem procesu, warunkami i FAQ - jest jednoznacznie umieszczony w przestrzeni semantycznej i trafia dokładnie tam, gdzie powinien.
System prompt vs. RAG - gdzie umieścić wiedzę
Jednym z najważniejszych wyborow przy wdrazaniu agentów AI jest decyzja, gdzie umieścić wiedzę: w system prompcie czy w bazie RAG. Teoretycznie niemal wszystko da się wrzucic do system promptu - instrukcje, procedury, FAQ, a nawet całe regulaminy. Problem w tym, że takie podejście ma powazne ograniczenia.
- ✕Ogromny koszt input-tokenów przy każdym zapytaniu
- ✕Każda rozmowa przetwarza cały prompt od nowa
- ✕Brak możliwości zarządzania - zmiana wymaga edycji promptu
- ✕Limit kontekstu modelu (128k-200k tokenów)
- ✕Trudne wersjonowanie i audyt zmian
- ✕Brak priorytetyzacji - model traktuje wszystko równo
- ✓Niski koszt - pobierane są tylko relevantne fragmenty
- ✓System prompt zawiera tylko instrukcje i ton
- ✓Wiedza zarządzana niezależnie od promptu
- ✓Brak limitu - baza RAG może być dowolnie duza
- ✓Latwe wersjonowanie, audyt i aktualizacja
- ✓Boostery i priorytety kieruja wyszukiwaniem
System prompt powinien zawierać: instrukcje zachowania agenta, ton komunikacji, zasady eskalacji, ograniczenia (czego agent nie powinien robic) i ogólne reguly dialogu. To „osobowosc” i „regulamin pracy” agenta.
Baza RAG powinna zawierać: konkretną wiedzę merytoryczna - procedury, FAQ, dane produktowe, cenniki, regulaminy, instrukcje krok-po-kroku. To „podręcznik”, z ktorego agent korzysta w razie potrzeby.
Jeśli informacja jest stala i dotyczy zachowania agenta (np. „zawsze mow po polsku”, „nie podawaj cen konkurencji”) - daj ja do system promptu. Jeśli informacja jest zmienna i dotyczy wiedzy merytorycznej (np. procedura reklamacji, cennik, FAQ) - umiesc ja w RAG. Dzięki temu system prompt pozostaje lekki (200–500 tokenów), a koszty są pod kontrola.
Każdy agent w X-TALK ma oddzielny profil z konfigurowalna rola, jezykiem i tonem komunikacji (system prompt), a także dedykowaną baze wiedzy (RAG). Rozdzielenie tych dwoch warstw pozwala na niezależne zarządzanie zachowaniem agenta i jego wiedza.
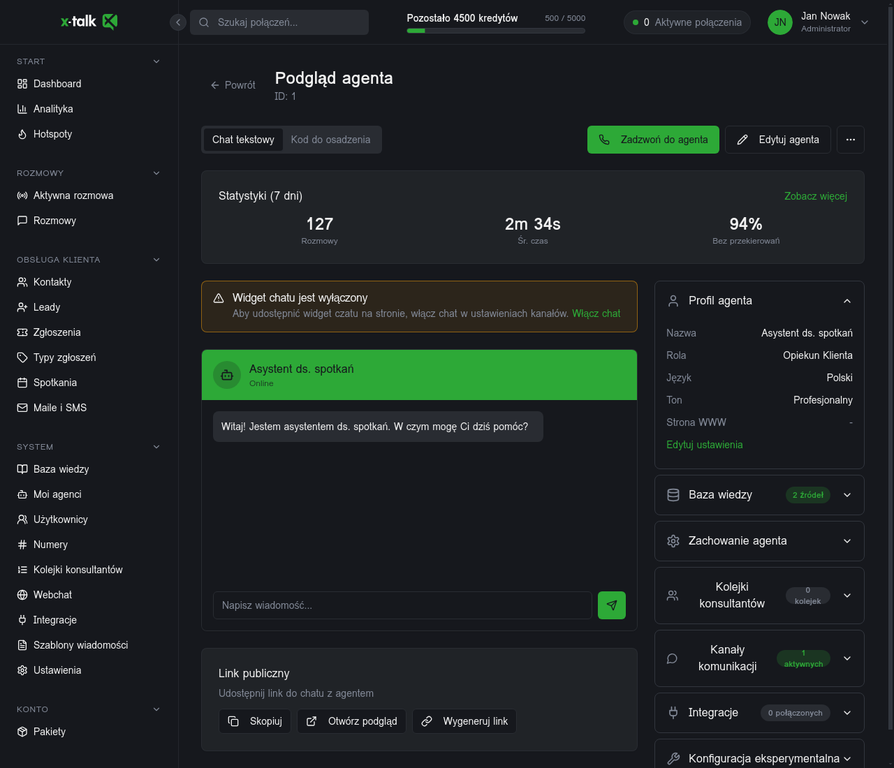
Profil agenta: rola i ton (system prompt) + baza wiedzy (RAG) - dwie niezależne warstwy
Formatowanie dokumentów dla RAG
Jakość odpowiedzi agenta AI zależy nie tylko od tego, co jest w bazie wiedzy, ale również od tego, jak dokumenty są sformatowane. W X-TALK stosujemy specjalny system metadanych YAML, który pozwala na inteligentne wzmacnianie (boostowanie) wyników wyszukiwania. Dzięki temu agent szybciej i trafniej znajduje odpowiednia procedurę.
---
procedurę_id: PROC-001
priority: HIGH
category: OPERACJE/SYSTEM
keywords: [haslo, reset, logowanie, dostep]
symptoms: [nie mogę się zalogowac, błąd hasla, zablokowane konto]
summary: Procedura resetu hasla uzytkownika
---
# Reset hasla uzytkownika
## Opis problemu
Uzytkownik nie może się zalogowac do systemu.
## Potencjalne przyczyny
- Zapomniane haslo
- Zablokowane konto po wielu próbach
- Wygasłe haslo
## Procedura rozwiązywania
1. Zweryfikuj tożsamość uzytkownika
2. Sprawdź status konta w panelu admina
3. Wykonaj reset hasla
4. Poinformuj o nowym hasle tymczasowym
## Weryfikacja
Uzytkownik potwierdził poprawne logowanie.Nagłówek YAML (frontmatter) na poczatku dokumentu zawiera metadane, które silnik RAG wykorzystuje do lepszego dopasowania dokumentu do zapytania klienta. Oto jak działają poszczególne pola i ich wpływ na scoring:
| Pole | Typ | Opis | Boost RAG |
|---|---|---|---|
| priority | string | CRITICAL, HIGH, NORMAL, LOW | CRITICAL +35%, HIGH +20% |
| keywords | array | Lista słów kluczowych i synonimów | +25% przy dopasowaniu |
| symptoms | array | Objawy/problemy z perspektywy klienta | +30% przy dopasowaniu |
| category | string | Kategoria dokumentu, np. OPERACJE/SYSTEM | Filtrowanie + badge |
| procedure_id | string | Unikalny identyfikator procedury | Szybkie wyszukiwanie |
| summary | string | Krótkie podsumowanie dokumentu | Podgląd wyników |
Jak działa scoring w praktyce? Gdy klient mowi „nie mogę się zalogowac”, silnik RAG dopasowuje to zapytanie do dokumentów. Dokument z symptoms: [nie mogę się zalogowac] dostaje +30% boost. Jeśli dodatkowo ma priority: HIGH, dostaje kolejne +20%. Dokument z keywords: [logowanie] dostaje +25%. Wynik końcowy decyduje, który dokument zostanie dostarczony agentowi jako kontekst odpowiedzi.
Keywords - dodawaj synonimy i potoczne nazwy (np. „haslo”, „password”, „login”, „dostep”). Symptoms - opisuj problem z perspektywy klienta, jego słowami („nie mogę się zalogowac”, „nie działa logowanie”). Priority - uzywaj CRITICAL tylko dla naprawde krytycznych procedur. Struktura - dziel dokument na sekcje: Problem, Przyczyny, Rozwiązanie, Weryfikacja. Obsługiwane formaty: .md, .txt, .pdf, .docx, .html.
Dobrze sformatowane dokumenty RAG to różnica miedzy agentem, który „cos tam odpowiada”, a agentem, który precyzyjnie rozwiązuje problem klienta w pierwszej interakcji. Inwestycja w jakość dokumentacji zwraca się wielokrotnie w postaci wyższego resolution rate.
Integracja z SharePoint i zarządzanie wersjami
W większości organizacji wiedza żyje w rozproszonych systemach - SharePoint, Confluence, Google Drive, lokalne dyski. Kluczowym wyzwaniem jest zapewnienie, że agenci AI zawsze pracuja na najświeższej wersji wiedzy, bez konieczności ręcznego kopiowania dokumentów.
X-TALK umożliwia integracje z SharePoint i innymi systemami zarządzania dokumentami. Dzięki temu aktualizacja procedury w SharePoint automatycznie aktualizuje wiedzę agenta. Nie ma ryzyka, że agent odpowiada na podstawie nieaktualnego dokumentu.
Warto pamiętać, że aktualizacja dokumentu w bazie RAG to nie jest proste „wrzucenie nowego pliku”. Każda zmiana wymaga kilku kroków: konwersja dokumentu do ustandaryzowanego formatu (markdown),chunking (podział na fragmenty), a przede wszystkim reindeksacja embeddingów - czyli ponowne przeliczenie wektorów semantycznych przez model embeddingowy. To generuje realne koszty u zewnętrznych operatorów (np. OpenAI, Cohere). Przy dużych bazach wiedzy i częstych zmianach warto zaplanować strategię aktualizacji - np. synchronizacja raz dziennie zamiast w czasie rzeczywistym - żeby zoptymalizować koszty bez utraty aktualności.
Zarządzanie wersjami to nie tylko kwestia techniczna - to kwestia zaufania. Jeśli agent udziela odpowiedzi na podstawie nieaktualnej procedury, może to prowadzić do błędów, frustracji klientów i strat finansowych. Dlatego każdy dokument w bazie RAG powinien miec:
- Jasno określone źródło prawdy (np. SharePoint, Confluence)
- Automatyczną synchronizację że źródłem - bez ręcznego kopiowania
- Wersjonowanie z możliwością porównania zmian (diff)
- Log zmian - kto, kiedy i co zmienił
- Możliwość rollbacku do poprzedniej wersji
- Alerty przy istotnych zmianach w kluczowych dokumentach
- Regularne audyty aktualności wiedzy (co miesiac / kwartal)
Wielojęzyczność - LLM vs RAG i wyzwania embeddingów
Jednym z najczęstszych pytań przy wdrożeniu centrum komunikacji AI jest: „Czy system obsłuży klientów w różnych językach?”Odpowiedź brzmi: tak, ale z istotnym zastrzeżeniem. O ile generowanie odpowiedzi w dowolnym języku jest dla modeli LLM trywialne, o tyle wyszukiwanie semantyczne w bazie wiedzy (RAG) to zupełnie inna historia.
Model językowy (GPT-4, Claude, Gemini) potrafi generować odpowiedzi w praktycznie dowolnym języku. Jeśli klient pisze po niemiecku, model odpowie po niemiecku - nawet jeśli baza wiedzy jest po polsku.
• Rozumie pytanie w dowolnym języku
• Generuje odpowiedź w języku klienta
• Tłumaczy kontekst „w locie”
Silnik RAG zamienia tekst na embeddingi (wektory matematyczne) i szuka podobieństwa. Problem: embeddingi są wrażliwe na język. Pytanie po niemiecku i dokument po polsku - to dwa różne punkty w przestrzeni wektorowej.
• Embeddingi różnią się per język
• Cross-language search pomaga, ale nie w 100%
• Wymaga świadomego podejścia do architektury
Klient pyta po niemiecku: „Wie kann ich mein Passwort zurücksetzen?”. LLM rozumie to pytanie bez problemu. Ale silnik RAG musi znaleźć odpowiedni dokument w bazie. Jeśli baza jest po polsku („Reset hasła użytkownika”), embedding niemieckiego pytania i polskiego dokumentu mogą się nie spotkać- bo modele embeddingowe były trenowane głównie na danych anglojęzycznych, a dopasowanie cross-language (np. DE → PL) ma niższy score niż dopasowanie w tym samym języku.
Dlaczego tak się dzieje? Modele embeddingowe (np. text-embedding-ada-002, BGE, E5) zamieniają tekst na wektory w przestrzeni wielowymiarowej. Teksty o tym samym znaczeniu powinny mieć bliskie wektory. W praktyce jednak modele te działają najlepiej wewnątrz jednego języka. Pytanie „reset hasła” i dokument „reset hasła” - oba po polsku - dadzą bardzo bliskie wektory. Ale „Passwort zurücksetzen” (DE) i „reset hasła” (PL) mogą mieć znacznie większą odległość wektorową, co oznacza niższy score dopasowania.
Nasz silnik RAG oferuje funkcję cross-language search, która częściowo rozwiązuje ten problem - tłumaczy zapytanie lub używa wielojęzycznych embeddingów. Mimo to, w praktyce produkcyjnej, najlepsze wyniki osiąga się stosując jedną z trzech strategii:
---
priority: HIGH
category: OBSŁUGA/ZWROTY
keywords: [zwrot, return, Rückgabe, retour]
keywords_de: [Rückgabe, Rücksendung, Erstattung]
keywords_en: [return, refund, send back]
symptoms: [chcę zwrócić, I want to return,
Ich möchte zurückgeben]
summary: Procedura zwrotu towaru
---
# Procedura zwrotu towaru
Klient chce zwrócić zakupiony produkt...
(dokument w języku głównym - polskim)Dodanie wielojęzycznych keywords i symptoms w YAML frontmatter znacząco poprawia dopasowanie cross-language. Nawet jeśli sam dokument jest po polsku, silnik RAG „zobaczy” niemieckie i angielskie słowa kluczowe w metadanych i da im odpowiedni boost (+25% dla keywords, +30% dla symptoms). To prosty sposób na poprawę wielojęzycznego wyszukiwania bez konieczności duplikowania całej bazy wiedzy.
| Aspekt | LLM (generowanie) | RAG (wyszukiwanie) |
|---|---|---|
| Rozumienie pytania | Natywne - rozumie ~100 języków | Zależne od modelu embeddingów |
| Generowanie odpowiedzi | W dowolnym języku, automatycznie | Nie dotyczy - RAG tylko wyszukuje |
| Dopasowanie dokumentów | Nie dotyczy - LLM nie szuka w bazie | Najlepsze w tym samym języku |
| Cross-language | Bezproblemowe | Możliwe, ale z niższym score |
| Koszt wielojęzyczności | Minimalny - wbudowane w model | Wymaga strategii i konfiguracji |
| Detekcja języka | Automatyczna | Konieczna - aby wybrać bazę lub tłumaczyć query |
W X-TALK stosujemy podejście hybrydowe: baza wiedzy w języku głównym organizacji, z wielojęzycznymi metadanymi w YAML. System automatycznie wykrywa język klienta, tłumaczy zapytanie na język bazy przed wyszukiwaniem RAG, a następnie LLM generuje odpowiedź w języku klienta. Dzięki temu firma utrzymuje jedną bazę wiedzy, a jednocześnie obsługuje klientów w wielu językach z wysoką precyzją dopasowania.
Wszystkie opisane techniki - query rewriting, reranking, multi-step search, tłumaczenie zapytań - są technicznie możliwe i dostępne w nowoczesnych silnikach RAG. Problem polega na tym, że każda z nich dodaje latencję i generuje koszty.
W czacie tekstowym dodatkowe 1–2 sekundy na przetworzenie zapytania są akceptowalne. Ale w voicebocie każda milisekunda się liczy. Klient czeka na odpowiedź w czasie rzeczywistym - cisza dłuższa niż 2–3 sekundy jest odbierana jako awaria systemu. Jeśli do standardowego wyszukiwania RAG dodamy tłumaczenie query (200–500ms), reranking (300–800ms) i ewentualny retry z przepisanym zapytaniem (kolejne 500–1000ms), łatwo przekroczymy próg akceptowalnej ciszy.
Wniosek jest prosty: im lepiej przygotowana baza wiedzy, tym mniej „sztuczek” potrzebnych w pipeline. Dobrze napisane dokumenty z precyzyjnymi keywords i symptoms w YAML trafiają za pierwszym razem - bez rerankingu, bez retry, bez tłumaczenia query. To oznacza:
przy dobrej bazie wiedzy
do przetworzenia
nienaturalnych pauz
Inwestycja w jakość bazy wiedzy to nie „nice to have” - to fundament płynnej rozmowy głosowej. Każda godzina spędzona na porządkowaniu dokumentów zwraca się w setkach szybszych, trafniejszych odpowiedzi.
- Określ języki, w których będziesz obsługiwać klientów
- Wybierz strategię: tłumaczenie query, dedykowane bazy czy podejście hybrydowe
- Dodaj wielojęzyczne keywords i symptoms do YAML frontmatter dokumentów
- Skonfiguruj automatyczną detekcję języka na wejściu
- Przetestuj dopasowanie RAG dla każdego obsługiwanego języka
- Monitoruj resolution rate per język - identyfikuj luki w pokryciu
- Rozważ dedykowaną bazę dla języków o dużym wolumenie zapytań
Podział wiedzy miedzy agentów
W systemie z wieloma agentami AI kluczowe jest przemyslane zarządzanie wiedza. Nie każdy agent powinien miec dostep do wszystkich informacji. Wlasciwy podział wiedzy zwiększa precyzję odpowiedzi, zmniejsza ryzyko błędów i optymalizuje koszty przetwarzania.
Informacje o firmie i marce
Regulaminy i polityki
Dane kontaktowe i godziny pracy
Ogolne zasady obsługi
Wiedza produktowa → agent sprzedaży
Procedury reklamacji → agent supportu
Skrypty kwalifikacji → agent lead gen
Dane techniczne → agent IT
Dobrze zaprojektowany podział wiedzy to jeden z największych wyróżników dojrzałego wdrożenia. Pozwala na precyzyjne odpowiedzi, szybsze przetwarzanie i mniejsze ryzyko „halucynacji” modelu. Każdy agent powinien operowac na minimalnym, ale wystarczającym zbiorze wiedzy dla swojego obszaru.
Projektowanie agentów i ich kompetencji
W zaawansowanym centrum komunikacji AI rzadko sprawdza się model jednego, wszechwiedzacego bota. Znacznie skuteczniejsze jest podejście oparte na wielu agentach o wyspecjalizowanych rolach. Każdy agent powinien miec jasno zdefiniowany zakres odpowiedzialności, styl komunikacji i zasady działania.

Agent sprzedażowy
Proaktywny, nastawiony na konwersję. Pomaga w wyborze produktu, odpowiada na pytania o ofertę, kwalifikuje leady i przekazuje gorące kontakty do handlowców.
Agent wsparcia technicznego
Cierpliwy, precyzyjny, skupiony na rozwiązywaniu problemów. Diagnozuje usterki, prowadzi przez procedury naprawcze, eskaluje złożone przypadki.
Agent intake / zgłoszeń
Zbiera dane, klasyfikuje zgłoszenia, tworzy tickety. Dopytuje o kluczowe informacje i kieruje sprawę do właściwej kolejki.
Agent pierwszego kontaktu
Rozpoznaje intencję, kieruje do właściwego agenta specjalistycznego lub konsultanta. Działa jak inteligentna recepcja.
Projektowanie agentów wymaga zdefiniowania nie tylko tego, co agent powinien robic, ale również tego, czego nie powinien. Jasne ograniczenia zapobiegają sytuacjom, w których agent podejmuje decyzję wykraczające poza jego kompetencje. Każdy agent powinien miec zdefiniowane warunki eskalacji - sytuacje, w których musi przekazać sprawę dalej.
Szczegółowy profil agenta w X-TALK: statystyki (127 rozmów, 94% bez przekierowań), wbudowany chat testowy, konfiguracja bazy wiedzy, kolejek konsultantów i kanałów komunikacji. Każdy agent to samodzielną jednostka z pełna kontrola nad jego zachowaniem.
Profil agenta: statystyki, chat testowy, baza wiedzy i konfiguracja zachowania
Jak budować system prompt - praktyczny przewodnik
System prompt to instrukcja operacyjna dla agenta AI. To nie jest miejsce na bazę wiedzy (od tego jest RAG) - to zbiór reguł, które definiują kim jest agent, jak się zachowuje i co powinien robić w konkretnych sytuacjach. Dobrze napisany system prompt to różnica między botem, który brzmi jak automat, a agentem, który prowadzi rozmowę jak doświadczony konsultant.
Zobaczmy to na konkretnych przykładach. Każdy poniższy system prompt jest uproszczony dla czytelności - w praktyce mogą być dłuższe - ale pokazuje kluczowe mechanizmy, które sprawiają, że agent działa skutecznie.
• Brak konkretnych reguł - agent zgaduje
• Nie wie, kiedy eskalować
• Nie wie, jakie dane zbierać
• Może wymyślać informacje o produktach
• Może udzielać rabatów bez autoryzacji
• Jasna tożsamość i ton komunikacji
• Konkretne kroki dla każdej sytuacji
• Twarde reguły eskalacji
• Wyraźne zakazy chronią firmę
• Agent wie, jakie dane zbierać i kiedy
| Branża | Kluczowe reguły w system prompcie | Typowe tool calls |
|---|---|---|
| E-commerce | Identyfikacja klienta → cel zakupu → budżet → rekomendacja 2-3 produktów. Reklamacje → eskalacja. Cross-sell max 1 na rozmowę. | search_products, get_order_status, check_stock, get_recommendations |
| Szkoła narciarska | Zbierz: dyscyplina + poziom + dzień + liczba osób. Potwierdź sklep partnerski ze słownikiem. Rezerwuj dopiero z kompletem danych. | check_availability, create_booking, verify_partner_shop |
| SaaS / IT | Identyfikacja konta → diagnoza problemu → sprawdź status usługi. Eskalacja przy problemach z płatnościami lub bezpieczeństwem. | get_account_status, check_service_health, create_ticket |
| Klinika / przychodnia | Zbierz: specjalizacja + preferowany termin + czy pierwsza wizyta. NIE diagnozuj. NIE doradzaj leków. | check_doctor_availability, create_appointment |
| Nieruchomości | Zbierz: typ (kupno/wynajem) + lokalizacja + budżet + metraż. Zaproponuj 2-3 oferty. Umów na oględziny. | search_properties, schedule_viewing, get_agent_calendar |
Ton komunikacji to nie ozdoba - to narzędzie biznesowe. Klient, który czuje się traktowany z szacunkiem, jest bardziej skłonny do zakupu, mniej skłonny do eskalacji i chętniej wraca. W system prompcie ton definiujesz konkretnymi regułami:
System prompt powinien odpowiadać na pytanie: "Co by zrobił najlepszy konsultant w tej sytuacji?" Jeśli najlepszy konsultant w sklepie internetowym najpierw pyta o potrzeby klienta, potem szuka w katalogu, a na końcu proponuje 2-3 opcje z uzasadnieniem - to dokładnie tak powinien działać Twój agent AI. System prompt to formalizacja tego, co najlepsi ludzie w Twojej firmie robią intuicyjnie.
- Zdefiniuj rolę i tożsamość agenta (firma, zakres, kanał)
- Określ ton komunikacji dopasowany do branży i klienta
- Wypisz reguły zbierania danych - co agent MUSI wiedzieć zanim podejmie działanie
- Zdefiniuj reguły decyzyjne - co robić w każdej typowej sytuacji
- Wypisz twarde zakazy - czego agent NIE powinien robić
- Określ warunki eskalacji - kiedy przekazać do człowieka
- Dodaj reguły cross-sell/upsell z ograniczeniami (max 1 na rozmowę, nie przy reklamacjach)
- Przetestuj prompt na 20 typowych scenariuszach zanim wdrożysz na produkcję
Routing, kolejki i przełączenia
Płynne przekazywanie spraw między agentami AI a ludźmi to jeden z najważniejszych aspektów projektowania centrum komunikacji. System powinien inteligentnie kierować zapytania do odpowiednich kolejek kompetencji, uwzględniając priorytety, dostępność konsultantów i kontekst sprawy.
Tradycyjny IVR to „naciśnij 1 dla sprzedaży, naciśnij 2 dla reklamacji” - frustrujące drzewko decyzji, w którym klient często trafia w ślepą uliczkę. Kolejki kompetencji w X-TALK to zupełnie inne podejście: agent AI prowadzi naturalną rozmowę, rozpoznaje intencję i sam kieruje sprawę do odpowiedniej kolejki - bez żadnego menu tonowego.
„Aby połączyć się z działem sprzedaży, naciśnij 1.”
„Aby zgłosić reklamację, naciśnij 2.”
„Aby sprawdzić status zamówienia, naciśnij 3.”
„Aby powtórzyć opcje, naciśnij 9.”
Klient musi słuchać całego menu, często trafia źle, frustracja rośnie.
„Dzień dobry, w czym mogę pomóc?”
„Chciałbym zareklamować ekspres do kawy.”
Agent rozpoznaje: intencja = reklamacja, produkt = ekspres.
Automatycznie kieruje do kolejki Reklamacje → AGD.
Klient mówi naturalnie, system sam decyduje gdzie skierować sprawę.
W X-TALK definiujesz kolejki kompetencji (np. Sprzedaż, Support techniczny, Reklamacje, VIP) i przypisujesz do nich konsultantów. Agent AI na podstawie rozpoznanej intencji i kontekstu rozmowy sam decyduje, do której kolejki skierować sprawę - bez drzewek decyzji, bez menu tonowego, bez „naciśnij 1”.
System nie czeka, aż klient poprosi o konsultanta - sam proponuje przełączenie, gdy wykryje sygnały eskalacji:
Kluczowa zasada: gdy klient prosi o człowieka, system nie próbuje go przekonać do dalszej rozmowy z AI. Natychmiast potwierdza i inicjuje przełączenie. Każda sekunda oporu to utrata zaufania.
Zanim system zaproponuje przełączenie do człowieka, musi wiedzieć czy ktoś jest dostępny. X-TALK sprawdza to w czasie rzeczywistym:
Klient: „Chciałbym porozmawiać z kimś o ofercie.”
System sprawdza: Kolejka „Sprzedaż” → harmonogram do 18:00 → brak konsultantów online.
Agent AI: „Nasz zespół sprzedaży pracuje do 18:00. Mogę zebrać Pana dane i umówić kontakt na jutro rano - kto powinien do Pana zadzwonić?”
Zamiast „konsultant jest niedostępny, zadzwoń później” - agent przejmuje inicjatywę i zbiera lead.
Handoff do człowieka musi odbywać się z zachowaniem pełnego kontekstu rozmowy. Konsultant przejmujący sprawę powinien mieć dostęp do historii interakcji, zebranych danych i zidentyfikowanej intencji klienta. Dzięki temu unika się frustrującej konieczności powtarzania tych samych informacji.
X-TALK nie tylko kieruje rozmowy do kolejek - analizuje ich efektywność w czasie rzeczywistym. Dashboard pokazuje:
| Metryka | Co mierzy | Dlaczego ważne |
|---|---|---|
| Obciążenie kolejki | Ile rozmów czeka / jest obsługiwanych w danej kolejce | Pozwala reagować na przeciążenia i przesuwać zasoby |
| Średni czas oczekiwania | Ile klient czeka na połączenie z konsultantem | Kluczowy wskaźnik satysfakcji - powyżej 60s klienci się rozłączają |
| Skuteczność per kolejka | % spraw rozwiązanych bez eskalacji wyżej | Pokazuje, które kolejki potrzebują lepszego szkolenia lub więcej osób |
| Czas obsługi po handoff | Ile trwa rozmowa z konsultantem po przełączeniu | Mierzy jakość pre-screeningu przez AI - im krótszy, tym lepszy kontekst |
| Rozkład godzinowy | Kiedy kolejki są najbardziej obciążone | Pozwala optymalizować harmonogramy konsultantów |
Historia rozmów z pełnym kontekstem: transkrypcja, podsumowanie AI, przypisane tagi, czas trwania i koszt kredytów. Przy przekazaniu do konsultanta - cały kontekst jest widoczny natychmiast.
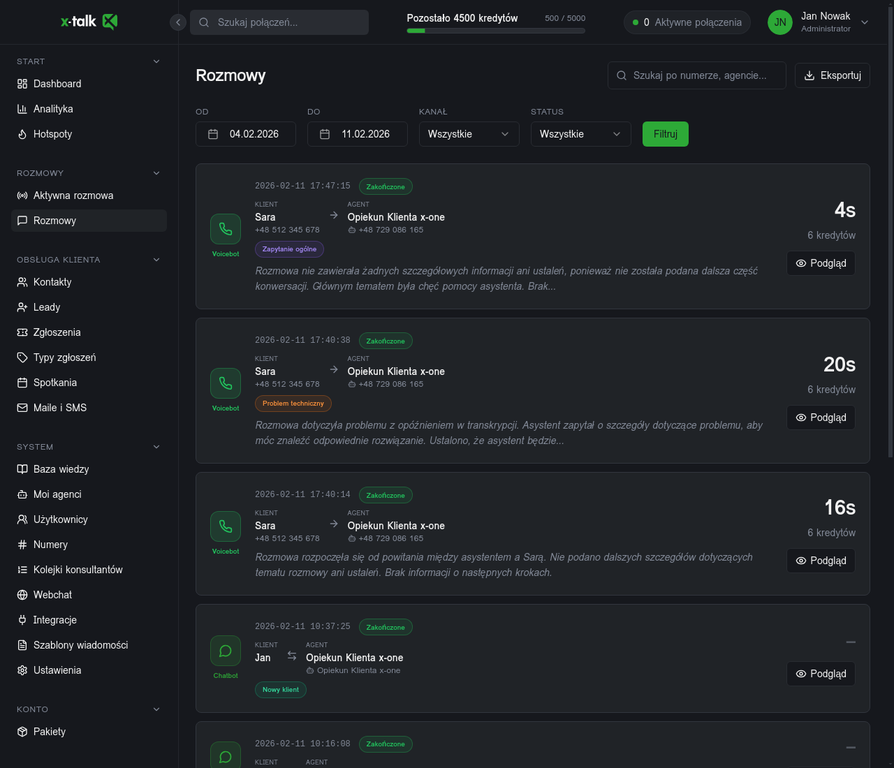
Lista rozmów z podsumowaniami AI, tagami i informacją o przekazaniach do konsultantów
- Zdefiniuj kolejki kompetencji (sprzedaż, support, reklamacje, VIP) i przypisz konsultantów
- Skonfiguruj harmonogramy pracy konsultantów - system musi wiedzieć, kto kiedy jest dostępny
- Ustal reguły kierowania oparte na intencji, priorytecie i dostępności
- Zdefiniuj sygnały eskalacji - frustracja, powtarzające się pytania, jawna prośba
- Zapewnij przekazanie pełnego kontekstu przy handoff do człowieka
- Wdróż mechanizm soft-queue z informacją o czasie oczekiwania
- Skonfiguruj fallback na callback gdy brak dostępnych konsultantów
- Zdefiniuj SLA dla każdego typu sprawy i kolejki
- Monitoruj obciążenie kolejek i optymalizuj harmonogramy na podstawie danych
Integracja z systemami zewnętrznymi - Tool Calling
Centrum komunikacji AI to nie zamknięty system - to warstwa inteligencji, która łączy się z istniejącą infrastrukturą firmy. Dzięki mechanizmowi tool calling (wywoływania narzędzi) agent AI potrafi w trakcie rozmowy odpytywać zewnętrzne systemy: CRM, ERP, kalendarz, helpdesk, system rezerwacji czy bazę produktową. To fundamentalna różnica między prostym chatbotem a prawdziwym centrum komunikacji.
Tool calling to mechanizm, w którym model językowy (LLM) rozpoznaje, że do udzielenia odpowiedzi potrzebuje danych z zewnętrznego systemu, a następnie generuje strukturalne zapytanie (JSON) do odpowiedniego API. Wynik zapytania wraca do kontekstu rozmowy i LLM buduje na jego podstawie naturalną odpowiedź. To nie jest „integracja w tle” - to agent AI, który aktywnie sięga po dane w czasie rzeczywistym.
„Chcę zarezerwować instruktora snowboardu na najbliższy czwartek”
To jedno zdanie klienta uruchamia cały łańcuch przetwarzania. Agent musi: rozpoznać intencję (rezerwacja), wyekstrahować zmienne (snowboard, czwartek), przetworzyć „najbliższy czwartek” na konkretną datę, dopasować słowniki do systemu rezerwacji i odpytać API o dostępność.
{
"tool": "booking_system.check_availability",
"parameters": {
"discipline": "snowboard",
"date": "2025-02-06",
"lesson_type": "individual",
"instructor_preference": null
}
}{
"available_slots": [
{ "time": "10:00", "instructor": "Marek K.", "price": 250 },
{ "time": "14:00", "instructor": "Anna W.", "price": 250 }
],
"lesson_duration": "2h",
"equipment_included": true
}Kluczowe jest zbieranie zmiennych. Agent AI musi wiedzieć, jakie parametry są wymagane przez API zewnętrznego systemu. Jeśli klient nie poda wszystkich informacji w jednym zdaniu, agent dopyta - ale robi to inteligentnie, zgodnie z zasadami psychologii dialogu (jedno pytanie zamiast pięciu).
Przetworzenie tool calla wygląda następująco: LLM analizuje kontekst rozmowy, rozpoznaje że potrzebuje danych z zewnętrznego systemu, generuje zapytanie w formacie JSON, system waliduje i wysyła zapytanie do API, odpowiedź wraca do kontekstu i LLM buduje na jej podstawie naturalną odpowiedź. Cały proces trwa typowo 1–3 sekundy.
| System | Zastosowanie | Przykład |
|---|---|---|
| System rezerwacji / cal.com | Sprawdzanie dostępności, tworzenie rezerwacji, zmiana terminów | Klient pyta o wolny termin → agent sprawdza kalendarz → proponuje godziny |
| CRM (Salesforce, HubSpot) | Identyfikacja klienta, historia interakcji, tworzenie leadów | Rozpoznanie klienta po numerze telefonu → pobranie historii zamówień |
| ERP / system magazynowy | Sprawdzanie stanów magazynowych, statusów zamówień, cen | Klient pyta o dostępność produktu → agent sprawdza stan w ERP |
| Helpdesk (Zendesk, Freshdesk) | Tworzenie ticketów, sprawdzanie statusu zgłoszeń | Klient zgłasza problem → agent tworzy ticket z pełnym kontekstem |
| System płatności | Sprawdzanie statusu płatności, generowanie linków do zapłaty | Klient pyta o status płatności → agent sprawdza i informuje |
| Baza produktowa / e-commerce | Wyszukiwanie produktów, porównywanie, rekomendacje | Klient szuka produktu → agent przeszukuje katalog i rekomenduje |
Bez tool callingu agent AI jest ograniczony do wiedzy statycznej - tego, co jest w bazie RAG. Z tool callingiem agent staje się aktywnym uczestnikiem procesów biznesowych: sprawdza dostępność, tworzy rezerwacje, otwiera tickety, identyfikuje klientów w CRM. To przejście od „odpowiadania na pytania” do „załatwiania spraw”.
Tool = definicja zadania + wymagane dane
W X-TALK nie musisz pisać kodu ani tworzyć JSON-ów ręcznie. Wszystko definiujesz w graficznym panelu - podajesz nazwę akcji, dodajesz wymagane pola, wybierasz ich typy z listy i zaznaczasz, które są obowiązkowe. System na tej podstawie automatycznie generuje definicję, którą rozumie LLM. To kluczowa koncepcja:definicja toola kieruje zachowaniem agenta.
Przykład: chcesz, żeby agent przyjmował reklamacje. W panelu X-TALK tworzysz nowy typ zgłoszenia, nadajesz mu nazwę i dodajesz pola - numer zamówienia, model produktu, opis problemu:
To, co zdefiniujesz w panelu, system automatycznie przekształca w strukturę zrozumiałą dla LLM. Pod spodem generuje się taka definicja:
{
"name": "submit_complaint",
"description": "Przyjmij reklamację od klienta",
"parameters": {
"order_number": {
"type": "string",
"required": true,
"description": "Numer zamówienia"
},
"product_model": {
"type": "string",
"required": true,
"description": "Model/nazwa reklamowanego produktu"
},
"issue_description": {
"type": "string",
"required": true,
"description": "Opis problemu zgłoszonego przez klienta"
},
"preferred_resolution": {
"type": "enum",
"options": ["wymiana", "zwrot", "naprawa"],
"required": false,
"description": "Preferowane rozwiązanie"
}
}
}Co się dzieje dalej? Gdy klient dzwoni i mówi „chcę złożyć reklamację”, LLM widzi definicję toola i wie, że potrzebuje numeru zamówienia, modelu sprzętu i opisu problemu. Agent sam prowadzi rozmowę tak, żeby te dane zebrać:
submit_complaint({
order_number: "ZAM-2025-4821",
product_model: "DeLonghi Magnifica",
issue_description: "Pompa do spieniania mleka nie działa",
preferred_resolution: null // klient nie wskazał preferencji
})Ty definiujesz w panelu, LLM robi resztę. Gdy w edytorze zaznaczysz pole jako wymagane, LLM nie wywoła toola, dopóki nie uzyska tej danej od klienta. Sam zdecyduje, jak o nią zapytać - naturalnie, w kontekście rozmowy. Nie musisz programować drzewa decyzyjnego. Wystarczy zdefiniować, co jest potrzebne, a LLM sam ustali jak to zebrać.
W sklepie internetowym tool calling zmienia agenta z „odpowiadacza na pytania” w aktywnego doradcę zakupowego. Agent nie tylko mówi o produktach z bazy wiedzy - może przeszukać katalog, sprawdzić stan magazynowy, porównać ceny i zaproponować produkty komplementarne.
- Zidentyfikuj systemy zewnętrzne, z którymi agent powinien się integrować
- Zmapuj dostępne API i ich wymagane parametry
- Zdefiniuj, jakie zmienne agent musi zebrać od klienta przed wywołaniem tool calla
- Przygotuj słowniki mapujące język naturalny na wartości API (np. 'snowboard' → discipline_id=2)
- Zaprojektuj obsługę błędów: co jeśli API nie odpowiada lub zwraca błąd?
- Przetestuj pełny flow: od pytania klienta przez tool call po odpowiedź AI
- Monitoruj czasy odpowiedzi API - każda milisekunda liczy się w voicebocie
Fallback, recovery i sytuacje trudne
Nawet najlepiej zaprojektowany system AI napotka sytuacje, z ktorymi sobie nie poradzi. Dojrzałość wdrożenia mierzy się nie tym, jak system radzi sobie z prostymi sprawami, ale tym, jak zachowuje się w sytuacjach trudnych.
Model nie zna odpowiedzi
Agent informuje o braku wiedzy, proponuje przekazanie do konsultanta lub utworzenie zgłoszenia. Nigdy nie wymyśla odpowiedzi.
Klient jest zdenerwowany
System rozpoznaje emocje, obniża napięcie, priorytetowo kieruje do człowieka. Zbiera podstawowe dane, aby konsultant mógł szybko pomóc.
Sprawa jest złożona
Agent zbiera maksimum informacji, klasyfikuje sprawę i przekazuje ją z pełnym kontekstem do odpowiedniego specjalisty.
Nierozpoznana intencja
System prosi o doprecyzowanie, proponuje najczęstsze tematy lub oferuje połączenie z konsultantem. Nie zostawia klienta w martwym punkcie.
Kluczowa zasada: lepiej uczciwie powiedzieć „nie wiem” i sprawnie przekazać sprawę, niż udzielić błędnej odpowiedzi. Dobrze zaprojektowany fallback buduje zaufanie klienta do systemu, nawet jeśli AI nie rozwiązało sprawy samodzielnie.
X-TALK automatycznie wykrywa problematyczne momenty w rozmowach: frustrację klienta, powtarzające się pytania, prośbę o konsultanta, nierozwiązane wątki. System proponuje konkretne akcje naprawcze: zmianę promptu, dodanie FAQ lub wcześniejszą eskalację.
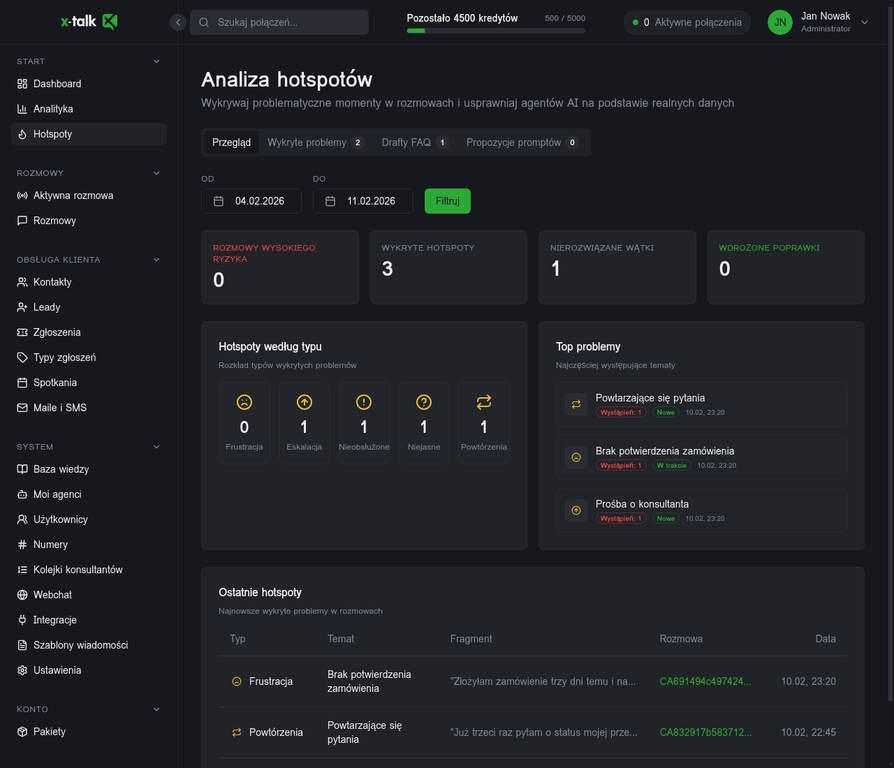
Hotspoty: automatyczne wykrywanie problemów i rekomendacje naprawcze
Gdy klient chce od razu człowieka
To jeden z najczęstszych scenariuszy i jednocześnie największa obawa firm wdrażających AI: „Co jeśli klient nie chce rozmawiac z botem?”. Odpowiedź jest prosta - nawet wtedy agent AI może dostarczyć ogromna wartość, nie blokujac klienta, ale przygotowując grunt pod szybszą obsługę przez człowieka.
Zanim klient zostanie połączony z konsultantem, agent AI może w kilka sekund:
- Zebrać cel kontaktu: W jakiej sprawie Pan/Pani dzwoni?
- Zidentyfikowac klienta - numer zamówienia, e-mail, numer klienta
- Zakwalifikować sprawę - sprzedaż, reklamacja, pytanie techniczne
- Ustalić priorytet - pilne, standardowe, informacyjne
- Przygotować kontekst dla konsultanta - podsumowanie w jednym zdaniu
- Zaproponować callback - jeśli konsultant jest zajety
- Otworzyć zgłoszenie - jeśli sprawa nie wymaga natychmiastowej rozmowy
Pełna transkrypcja rozmowy z analiza AI: automatyczne tagi (np. 'Status zamówienia' z 95% pewnoscia), ocena jakości rozmowy, wykryte hotspoty i rekomendowane akcje. Konsultant przejmujacy sprawę widzi cały kontekst.
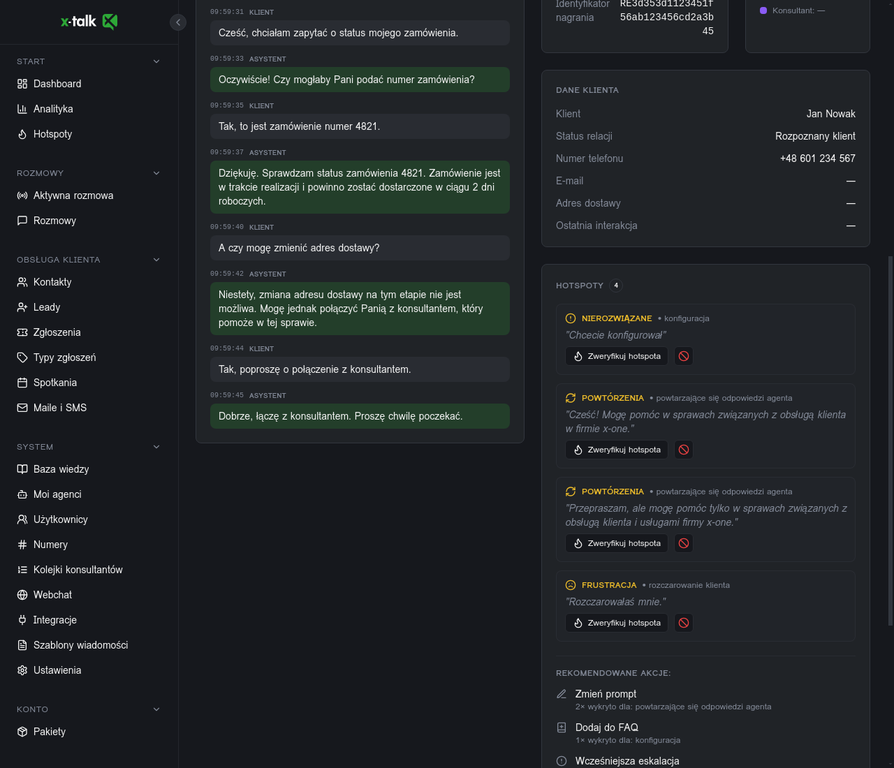
Transkrypcja z analiza AI: tagi, hotspoty, ocena jakości i dane klienta
Nawet 30-sekundowa interakcja z agentem AI przed połączeniem z konsultantem może skrócić czas obsługi o 40–60%. Konsultant nie musi pytać o podstawowe dane - dostaje je gotowe. To korzyść zarówno dla firmy, jak i dla klienta.
Lead capture i obsługa prośb o oddzwonienie
Centrum komunikacji AI to nie tylko narzędzie obsługi - to również potężny silnik generowania leadów. Agent AI potrafi rozpoznać intencję zakupową, zebrać dane kontaktowe, zakwalifikować temat i przekazać sprawę do handlowca z pełnym kontekstem.
Callback flow to szczegolnie wartościowy mechanizm. Gdy konsultant lub handlowiec nie jest dostępny, agent AI zbiera dane, ustala preferowany czas kontaktu i tworzy zadanie w systemie. Klient nie czeka na linii - wie, że ktos do niego oddzwoni. Firma nie traci leada - ma pełne dane i kontekst.
Dobrze zaprojektowany lead capture potrafi zwiększyć konwersję o 20–35%, ponieważ eliminuje najczęstszą przyczynę utraty leadów: brak natychmiastowej reakcji na zapytanie. Agent AI reaguje w sekundy, 24 godziny na dobę, 7 dni w tygodniu.
W e-commerce lead capture to nie tylko zbieranie danych kontaktowych. To także ratowanie porzuconych koszykow. Gdy klient pyta o produkt, porównuje opcje, ale nie finalizuje zakupu - agent może zaproponować pomoc lub callback.
System zgłoszeń w X-TALK: automatyczne tworzenie ticketów z rozmów, klasyfikacja (Reklamacja, Zapytanie, Usterka), sledzenie statusów (Nowy, W trakcie, Rozwiązany) i przypisywanie do odpowiednich osob. Agent AI tworzy zgłoszenie z pełnym kontekstem rozmowy.
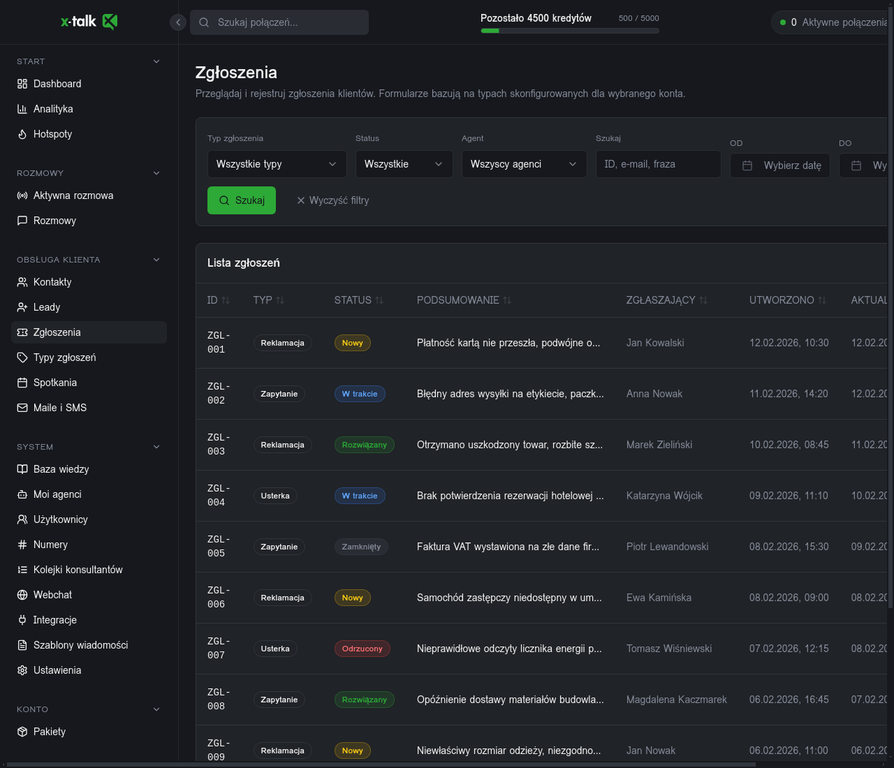
Zgłoszenia tworzone automatycznie z rozmów - pełny cykl życia ticketu
Psychologia dialogu AI
Projektowanie rozmów prowadzonych przez AI to nie tylko kwestia techniczna - to psychoinzynieria dialogu. Sposob, w jaki agent formułuje pytania, reaguje na emocje i prowadzi rozmowe, ma bezpośredni wpływ na skuteczność obsługi i satysfakcję klienta.
| Zasada | Opis | Przykład |
|---|---|---|
| Obniżanie napięcia | Uznanie emocji klienta przed przejściem do rozwiązania | Rozumiem, że ta sytuacja jest frustrująca. Zajmę się tym od razu. |
| Nie blokuj użytkownika | Zawsze dawaj opcję wyjścia lub eskalacji | Mogę pomóc w tej sprawie lub połączyć z konsultantem - co wolisz? |
| Prowadź do celu | Każde pytanie powinno przybliżać do rozwiązania | Zamiast 'Jak mogę pomóc?' lepiej: 'Czy chodzi o zamówienie, zwrot czy coś innego?' |
| Redukuj chaos | Zadawaj pytania zamknięte, gdy sprawa jest niejasna | 'Czy problem dotyczy ostatniego zamówienia?' zamiast 'Opisz swój problem' |
| Projektuj pod resolution | Dialog ma rozwiązać sprawę, nie tylko ładnie odpowiedzieć | Zamiast ogólnej odpowiedzi - konkretne kroki do wykonania |
| Zasada jednego zdania | Jedno otwierające zdanie zamiast serii pytań | Powiedz kogo, na co i na kiedy chcesz umówić, a ja zajmę się resztą. |
Jedno zdanie zamiast pięciu pytań - jak skrócić rozmowę o 30%
Dlaczego to działa? Jedno otwierające zdanie, które mówi klientowi co ma powiedzieć, uruchamia naturalny dialog. Klient odpowiada pełnym zdaniem zamiast jednego słowa, co daje systemowi STT (speech-to-text) więcej kontekstu do poprawnej transkrypcji. Agent dostaje od razu 3–4 informacje zamiast jednej, więc nie musi zadawać kolejnych pytań.
Ta zasada - „jedno zdanie zamiast pięciu pytań” - to fundament projektowania dialogow AI, szczegolnie w kanale głosowym. Oto praktyczne reguly, które z niej wynikaja:
Zamiast iterować przez liste pol (imię, temat, data, godzina, uwagi), zaprojektuj jedno otwierające zdanie, które zachęca klienta do podania wielu informacji naraz. Klient sam powie tyle, ile chce - a agent dopyta o brakujace elementy.
Agent nie powinien recytować listy opcji („Mamy narty, snowboard, sanki, łyżwy...”). Zamiast tego niech pyta o cel klienta i dopasowuje odpowiedź. Jeśli masz 10 punktów do omówienia - przeczytaj 1–2 najważniejsze i zapytaj, czy zrobione.
Zamiast zbierać wszystkie dane i potwierdzać na końcu („Czy wszystko się zgadza: imię, data, godzina, typ...?”), potwierdzaj po każdych 1–2 informacjach. „Córka, narty, sobota - dobrze rozumiem? Świetnie, o której godzinie?”
W rozmowie telefonicznej klient nie widzi opcji na ekranie. Dluzsze wypowiedzi klienta dają lepszy kontekst dla STT. Krótkie odpowiedzi („tak”, „nie”, „narty”) są trudniejsze do rozpoznania niż pełne zdania.
Cross-sell i upsell w rozmowie głosowej wymaga innego podejścia niż na stronie internetowej. Klient nie widzi banerów „Klienci kupili również...”. Agent musi zaproponować naturalnie, w kontekście rozmowy, i wiedzieć, kiedy NIE proponować.
Dialog AI powinien być zaprojektowany pod resolution, nie pod „ładne odpowiedzi”. Każda interakcja powinna przybliżać klienta do rozwiązania jego sprawy. To wymaga przemyślanego projektowania ścieżek rozmowy, testowania na rzeczywistych scenariuszach i ciągłej optymalizacji na podstawie danych.
Jak mierzyć skuteczność
Wdrożenie centrum komunikacji AI bez systemu pomiaru to jak jazda samochodem bez deski rozdzielczej. Musisz wiedzieć, co działa, co wymaga poprawy i gdzie tracisz klientów. Oto kluczowe wskaźniki efektywności (KPI), które powinieneś monitorować.
Regularne monitorowanie tych wskaźników pozwala na ciągłą optymalizację systemu. Warto ustalić cele dla każdego KPI i regularnie je przeglądać. Na przykład, jeśli fallback frequency jest wysoki w określonej kategorii spraw, może to oznaczać lukę w bazie wiedzy, która trzeba uzupełnić.
Dashboard X-TALK w czasie rzeczywistym: ilość połączeń, procent obsłużonych przez agenta, średni czas rozmowy i odpowiedzi, rozkład połączeń wg godzin, zużycie kredytów i rozkład obsługi (agent vs konsultant). Wszystkie KPI w jednym miejscu.
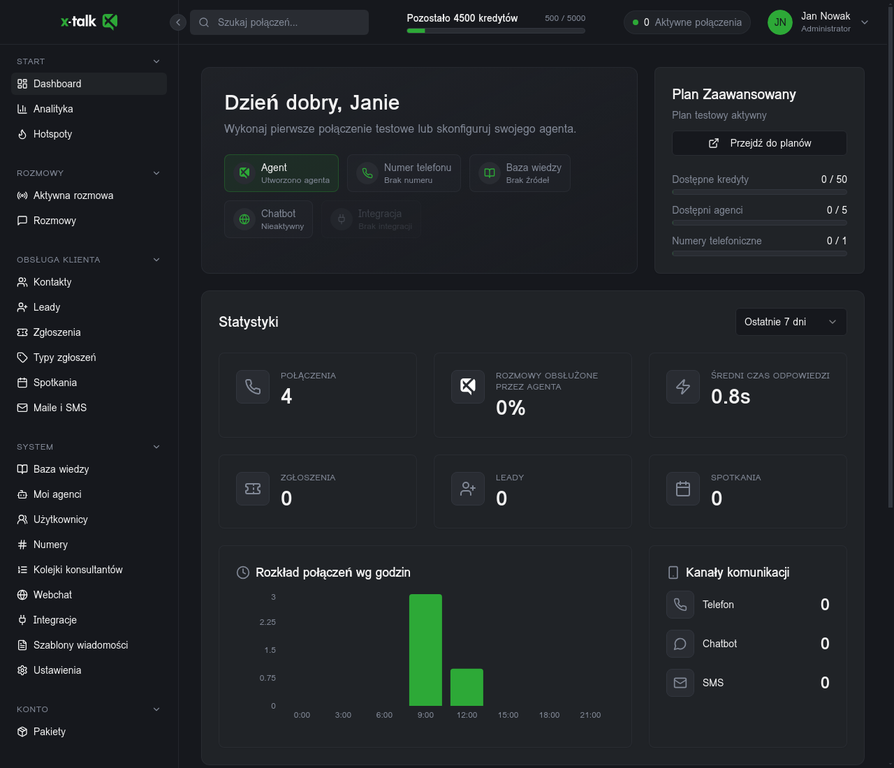
Dashboard: KPI w czasie rzeczywistym - połączenia, czas obsługi, zużycie kredytów
Analiza post-factum: tagi, hotspoty i podsumowania AI
Wdrożenie centrum komunikacji AI to nie jest projekt z data zakończenia. To żywi system, który wymaga ciągłej optymalizacji. Kluczem do tej optymalizacji jest analiza post-factum - systematyczne badanie tego, co dzieje się w rozmowach po ich zakończeniu. Bez niej działasz na ślepo: nie wiesz, gdzie agent sobie nie radzi, jakie tematy dominuja i co frustruje klientów.
Analiza post-factum odpowiada na fundamentalne pytania: O czym rozmawiaja klienci? Gdzie agent nie ma odpowiedzi? Co irytuje uzytkownikow? Jakie tematy rosną w sile? Te informację są bezcenne - pozwalają proaktywnie reagować, zamiast czekac na eskalację.
Automatyczne tagowanie
System analizuje transkrypcje rozmów i automatycznie przypisuje tagi tematyczne (np. 'reklamacja', 'pytanie o cenę', 'problem techniczny'). Tagi są definiowane przez Ciebie - możesz tworzyć własne kategorie dopasowane do specyfiki firmy. Dzięki temu każda rozmowa jest natychmiast sklasyfikowana bez ręcznej pracy konsultantów.
Analiza hotspotów
System automatycznie wykrywa problematyczne momenty w rozmowach: frustrację klienta, powtarzające się pytania bez odpowiedzi, prośby o konsultanta, nierozwiązane wątki. Każdy hotspot to sygnał - brakuje wiedzy w bazie, agent źle reaguje lub ścieżka obsługi wymaga korekty. System proponuje konkretne akcje naprawcze.
Podsumowania rozmów AI
Po każdej rozmowie system generuje zwięzłe podsumowanie: temat, intencja klienta, podjęte działania, wynik. Konsultant przejmujący sprawę nie musi czytać całej transkrypcji - dostaje esencję w 2–3 zdaniach. To także materiał do raportów i analiz trendów.
Analiza trendów i wzorców
Agregacja tagów i hotspotów w czasie pozwala wykrywać trendy: rosnąca liczbą pytań o dany produkt, sezonowe szczyty reklamacji, powtarzające się problemy techniczne. Te dane pozwalają proaktywnie reagować - zanim problem stanie się kryzysem.
Analiza sentymentu
System ocenia ton emocjonalny rozmowy: pozytywny, neutralny, negatywny. Pozwala to identyfikować rozmowy wymagające uwagi, mierzyć ogólny poziom satysfakcji i porównywać jakość obsługi między agentami lub okresami.
Ta pętla działa w sposób ciągły. Każda rozmowa generuje dane, które wracaja do systemu jako input do poprawy. Im więcej rozmów, tym lepsze dane. Im lepsze dane, tym precyzyjniejsze korekty. To samouczący się system, który z każdym tygodniem staje się skuteczniejszy.
| Korzyść | Jak to działa w praktyce |
|---|---|
| Identyfikacja luk w bazie wiedzy | Hotspoty pokazują, gdzie agent nie ma odpowiedzi - to bezpośredni input do uzupełnienia bazy wiedzy |
| Optymalizacja promptów | Analiza rozmów ujawnia, gdzie agent źle reaguje lub nie rozumie intencji - można precyzyjnie poprawić instrukcje |
| Szkolenie zespołu | Podsumowania i tagi dają menedżerom pełny obraz obsługi bez konieczności odsłuchiwania każdej rozmowy |
| Raportowanie dla zarządu | Automatyczne tagi i trendy to gotowy materiał na raporty: wolumen, tematy, sentyment, resolution rate |
| Ciągła poprawa jakości | Pętla zwrotna: analiza → identyfikacja problemu → korekta → pomiar efektu → kolejna analiza |
X-TALK automatycznie identyfikuje hotspoty w rozmowach: momenty frustracji, brak odpowiedzi, prośby o konsultanta. Każdy hotspot zawiera kontekst, sugerowaną akcję naprawczą i priorytet. Dzięki temu wiesz dokładnie, co poprawić i w jakiej kolejności.
Hotspoty: automatyczna identyfikacja problemów w rozmowach z sugerowanymi akcjami naprawczymi
Każda rozmowa w X-TALK ma pełna transkrypcję, automatyczne podsumowanie AI, przypisane tagi tematyczne, czas trwania i koszt. Konsultant przejmujacy sprawę widzi esencję rozmowy w 2\u20133 zdaniach, bez konieczności czytania całej historii.
Szczegóły rozmowy: transkrypcja, podsumowanie AI, tagi i statystyki
Większość firm mierzy tylko ile rozmów obsłużył agent. Analiza post-factum pozwala mierzyć jak je obsłużył. To różnica miedzy patrzeniem na licznik przebiegniętych kilometrów a diagnostyka silnika. Tagi, hotspoty i podsumowania to Twoj system wczesnego ostrzegania - pokazuja problemy, zanim staną się kryzysem.
- Zdefiniuj własne tagi dopasowane do specyfiki firmy (np. 'reklamacja', 'pytanie o cene', 'problem techniczny')
- Włącz automatyczne tagowanie rozmów na podstawie transkrypcji
- Regularnie przeglądaj hotspoty — każdy to sygnał do poprawy bazy wiedzy lub promptu
- Wykorzystuj podsumowania AI do szybkiego onboardingu konsultantów i raportowania
- Monitoruj trendy w tagach — rosnąca kategoria może sygnalizować problem z produktem
- Analizuj sentyment rozmów — spadek może oznaczać pogorszenie jakości obsługi
- Zamykaj pętle: analiza → korekta → pomiar efektu → kolejna analiza
Anatomia kosztów - co generuje koszty w centrum AI
Jednym z najczęstszych pytań decydentów jest: „Ile to kosztuje na rozmowę?”Odpowiedź nie jest prosta, bo koszt zależy od wielu zmiennych - długości rozmowy, złożoności sprawy, liczby tool calli, długości system promptu. Ale warto rozumieć anatomię kosztów, żeby świadomie optymalizować i nie przepłacać.
Poniższy wykres pokazuje orientacyjny udział poszczególnych składników w całkowitym koszcie obsługi rozmowy głosowej. Proporcje mogą się różnić w zależności od specyfiki wdrożenia, ale dają dobry obraz tego, gdzie leżą główne koszty.
Trzy największe składniki kosztowe (STT + LLM + TTS) stanowią łącznie ponad 70% kosztu rozmowy. To ważna informacja, bo każdy z nich można optymalizować:
STT jest naliczane za cały czas połączenia, bo system nasłuchuje nieprzerwanie.
Wniosek: im krótsza rozmowa, tym niższy koszt STT. Dlatego zasada „jednego zdania” z rozdziału o psychologii dialogu bezpośrednio obniża koszty.
Największy składnik kosztowy. W voice system prompt musi być rozbudowany - instrukcje zachowania, reguły fonetyczne, interpretacja STT, definicje tooli. Do tego historia dialogu i wyniki RAG.
Wniosek: krótki system prompt + wiedza w RAG (nie w prompcie) + precyzyjne definicje tooli = niższy koszt. Dlatego rozdział o „System prompt vs RAG” ma bezpośredni wpływ na budżet.
TTS jest naliczane za liczbę znaków. Każdy znak odpowiedzi kosztuje.
Wniosek: zwięzłe odpowiedzi agenta nie tylko brzmią lepiej, ale też kosztują mniej. Instrukcja w prompcie „odpowiadaj krótko i na temat” to jednocześnie optymalizacja UX i kosztów.
Przy każdym wywołaniu LLM system wysyła cały kontekst: system prompt (instrukcje agenta), historię dotychczasowego dialogu, definicje wszystkich dostępnych tooli, wyniki wyszukiwania RAG. Im dłuższa rozmowa, tym więcej tokenów w historii. Im więcej tooli, tym większy kontekst. Im dłuższy system prompt, tym wyższy bazowy koszt każdego wywołania. Dlatego architektura wiedzy (RAG vs prompt) i projektowanie tooli mają bezpośredni wpływ na koszty.
| Składnik | Jednostka rozliczeniowa | Co wpływa na koszt | Jak optymalizować |
|---|---|---|---|
| STT | Czas połączenia (sekundy) | Długość rozmowy, pauzy, cisza | Krótsze dialogi, zasada jednego zdania |
| LLM input | Tokeny wejściowe | System prompt, historia, toole, RAG | Krótki prompt, wiedza w RAG nie w prompcie |
| LLM output | Tokeny wyjściowe | Długość odpowiedzi agenta | Instrukcja zwięzłości w prompcie |
| TTS | Znaki do przetworzenia | Długość odpowiedzi tekstowej | Zwięzłe odpowiedzi, unikanie powtórzeń |
| Połączenie | Minuty | Czas trwania rozmowy | Efektywny dialog, szybka rezolucja |
| Analizy | Długość transkrypcji | Liczba włączonych analiz | Selektywne włączanie analiz |
| Storage | GB / miesiąc | Wolumen rozmów, retencja | Polityka retencji, kompresja |
| Tool calls | Wywołania API | Złożoność sprawy | Precyzyjne definicje tooli |
- Rozumiesz strukturę kosztów i wiesz, które składniki dominują w Twoim przypadku
- System prompt jest krótki i zwięzły - wiedza jest w RAG, nie w prompcie
- Definicje tooli są precyzyjne - tylko niezbędne parametry
- Agent odpowiada zwięźle - instrukcja w prompcie ogranicza gadatliwość
- Dialogi są efektywne - zasada jednego zdania skraca rozmowy o 20-30%
- Analizy post-factum są włączone selektywnie - nie wszystko na raz
- Polityka retencji nagrań jest zdefiniowana - nie przechowujesz danych w nieskończoność
- Monitorujesz koszt per rozmowa i reagujesz na anomalie
X-TALK AI Communication Center Framework
Wdrożenie centrum komunikacji AI to proces, który wymaga ustrukturyzowanego podejścia. Poniżej przedstawiamy 6-etapowy framework, który pozwala na systematyczne i skuteczne przeprowadzenie transformacji - od audytu po ciągłą optymalizację.
Mapowanie kanałów i spraw
Analiza obecnego stanu komunikacji. Identyfikacja kluczowych kanałów, typów zapytań, wolumenów i powtarzalności. Określenie, które obszary dają największy potencjał do automatyzacji.
Segmentacja wiedzy
Przygotowanie i uporządkowanie bazy wiedzy. Podział na kategorie (publiczna, procesowa, operacyjna, ekspercka). Określenie zasad dostępu i aktualizacji. Czyszczenie i strukturyzacja danych.
Projekt agentów i kompetencji
Zdefiniowanie ról, odpowiedzialności i tonu komunikacji agentów AI. Określenie zakresu decyzji, ograniczeń i warunków eskalacji dla każdego agenta.
Routing, fallback i handoff
Zaprojektowanie ścieżek przekazywania spraw, mechanizmów awaryjnych i zasad współpracy z zespołem ludzkim. Konfiguracja kolejek, priorytetów i SLA.
Integracje i automatyzacje
Połączenie systemu AI z istniejącymi narzędziami (CRM, helpdesk, e-commerce, kalendarz). Automatyzacja procesów: callback, tworzenie ticketów, aktualizacja statusów.
Pomiar i optymalizacja
Monitorowanie kluczowych KPI. Analiza jakości rozmów, trafności routingu i skuteczności resolution. Ciągłe doskonalenie bazy wiedzy, promptów i ścieżek obsługi.
Nie próbuj wdrożyć wszystkiego naraz. Zacznij od jednego kanału i jednego typu spraw. Przetestuj, zmierz, zoptymalizuj. Dopiero potem rozszerzaj. Jedno dobrze wdrożone rozwiązanie jest warte więcej niż dziesięć niedokończonych.
Gotowy na następny krok?
Platforma x-talk to AI-first consultant platform, która przejmie na siebie pierwszy ruch. Porozmawiajmy o tym, jak centrum komunikacji AI może wyglądać w Twojej firmie.